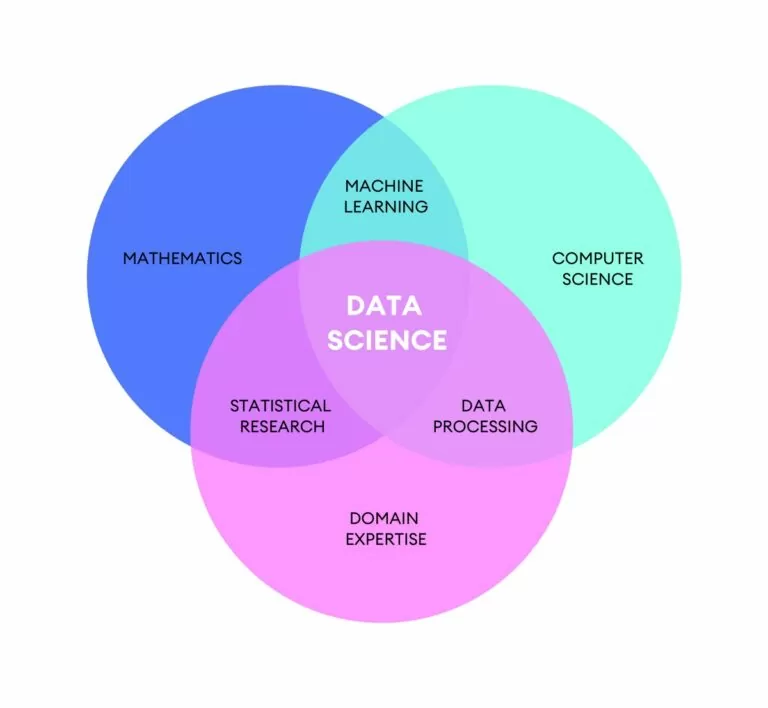
La Data Science, או Data Science, הוא מדע חדש יחסית, למעשה הוא קיים כחמישים שנה. זה נובע מהצורך לעשות סדר בהקשר מאוד חי ומתפתח במהירות. הגידול בנפח הנתונים, האפשרות והיכולת לתת משמעות לנתונים, הפכו את Data Science.
מבחינה היסטורית, נתונים טופלו לעתים קרובות כסוג של תוצר משני של כל תהליך. כל מי שהתחייב לאסוף נתונים במשך מאות שנים עשה זאת בעיקר לנוחותו, לעתים קרובות מבלי לדמיין את זה כיום ניתן לייחס ערך כלכלי לאוסף נתונים. אם נחשוב, למשל, על חווה שבמשך השנים אולי אספה מידע על יבולים, אירועים, זריעה וכו', אולי היא הייתה יכולה לעשות זאת כדי לאחסן את ההיסטוריה הארגונית שלה. אם כל החוות היו עושות את השיטה הזו, אז חברות הדשנים יכלו להרוויח ממנה כעת למטרות מחקר, או למטרות שיווק.
זה שמתעסק עם Data Science, קוראים לו מדען נתונים: כיום אחד מאנשי המקצוע המבוקשים בעולם העבודה.
המשימה של מדען הנתונים היא לנתח נתונים על מנת לזהות בתוכם מודלים, כלומר מה אני מבטא את הנתונים הזמינים דרך המגמה. זיהוי המודלים הללו הוא פונקציונלי למטרות הלקוח: חברה, גוף ציבורי וכו'...
בשנים האחרונות התבסס יותר ויותר מודל שיווק נתונים שבו מישהו מעוניין למכור נתונים ומישהו אחר לקנות אותם.
נולדו חברות המתמחות בייצור נתונים וחברות מתמחות בקנייה ומכירה לאחר פעולות ניקוי ועיבוד מתאימות. אם נחשוב אז על תקנות הפרטיות, אנו מבינים את מורכבות הנושא. כיום ישנם חוקים נוקשים הקוראים לשימוש מודע ומכבד במידע.
פרויקט של Data Science בדרך כלל מורכב מהשלבים הבאים:
בכל שלב ושלב ה מדען נתונים מקיים אינטראקציה עם מחלקות ספציפיות של החברה, ולכן אנו יכולים לומר כי מדען נתונים משולב בצורה מושלמת במציאות הארגונית.
עם הקידמה הטכנולוגית, ה מדען נתונים הוא מצא את עצמו לעתים קרובות מתמודד עם בעיות של ביג דאטה ובינה מלאכותית.
כשאנחנו מדברים על Big Data אנחנו מתייחסים לנתונים שמכילים מגוון גדול, שמגיעים בהיקפים הולכים וגדלים ובמהירות רבה יותר. מושג זה ידוע גם בתור כלל שלושת ה-V, המורכב מבחירה של שלושה מונחים המאפיינים את תופעת הביג דאטה במאפייניה המהותיים:
במציאות, נוספו עם הזמן גם מוזרויות אחרות, כמו אמיתות הנתונים כדי לזהות את מהימנותם ומהימנותם של הנתונים.
נפח גדול של נתונים המגיע במהירות רבה, ומאופיין במגוון רב, מוביל בהכרח לבעיות בארגון הנתונים.
לקבל אותם בברכה ואז לעבד אותם? מבנה אותם ואז מעבד אותם?
נולדו פרדיגמות שונות של ארגון מערכות נתונים, שהתבססו עם הזמן:
נכון לעכשיו אלו הן הפרדיגמות הנפוצות ביותר, ובמקרים רבים פתרון האינטגרציה מנצח, כלומר פרויקטים שונים יכולים להשתמש במתודולוגיות צבירה שונות ואז להשתלב במועד מאוחר יותר. יכולים להיות מצבים שבהם נאספים נתונים שונים עם פרדיגמות שונות, או שאוספים שונים יכולים להוות שלבים רציפים של אותו מחזור חיים.
למרות התועלת הרבה שלהם, אנחנו יודעים היטב שמכונות עיבוד או מחשבים הם טיפשים. כלומר, מחשב לא יכול לעשות כלום אם זה לא הבן אדם לנתח בעיה, לנסח אלגוריתם ולקודד אותה בתוכנית.
זה תמיד היה המצב, עד שהתחלנו לדבר על בינה מלאכותית. למעשה, בינה מלאכותית מורכבת מהשראת סוג של חשיבה ספונטנית במכונה, שיכולה להוביל אותה לפתור בעיות באופן עצמאי, כלומר ללא הדרכה אנושית ישירה.
עברו כמה שנים עד שהביטוי "לגרום לסוג של חשיבה ספונטנית במכונה", כלומר, עברו מספר שנים עד שעברנו ממצב של הוראה כפויה מוחלטת של המכונה, למצב של למידה עצמית. במילים אחרות, המכונה הצליחה ללמוד בעצמה, ללמוד. לכן הגענו ל למידת מכונה.
Machine Learning הוא ענף של בינה מלאכותית שבו המתכנת מניע את המכונה בשלב הדרכה המבוסס על חקר נתונים היסטוריים. בסופו של שלב הכשרה זה מופק מודל שניתן ליישם בפתרון בעיות, מוסבר עם נתונים חדשים.
אני מכבד את הגישה הקלאסית, שבה עבד מדען הנתונים defiלאחר אלגוריתמי פתרון, המכונה תגלה מה מרכיב את הדגם. על מדען הנתונים לדאוג לארגון שלבי הכשרה אפקטיביים יותר ויותר, עם נתונים עשירים ומשמעותיים יותר, ולוודא תקפות המודלים המיוצרים על ידי העמדתם למבחנים.
הודות ל-Machine Learning, המערכות בהן אנו משתמשים במכשירים ניידים, אינטרנט, אוטומציה ביתית הן (או נראות) אינטליגנטיות יותר ויותר. מערכת, כפי שהיא פועלת, עשויה גם להיות מסוגלת לאסוף נתונים עליה ועל המשתמשים שמשתמשים בה, ולאחר מכן להשתמש בהם בשלב ההדרכה ולאחר מכן לשפר עוד יותר את התחזיות.
Ercole Palmeri: מכור לחדשנות
Microsoft Excel הוא כלי ההתייחסות לניתוח נתונים, מכיוון שהוא מציע תכונות רבות לארגון מערכי נתונים,...
Walliance, SIM ופלטפורמה בין המובילות באירופה בתחום מימון המונים בנדל"ן מאז 2017, מכריזה על השלמת...
Filament הוא מסגרת פיתוח "מואצת" של Laravel, המספקת מספר רכיבים מלאים. זה נועד לפשט את התהליך של...
"אני חייב לחזור כדי להשלים את האבולוציה שלי: אני אשליך את עצמי בתוך המחשב ואהפוך לאנרגיה טהורה. לאחר שהתמקמו…
Google DeepMind מציגה גרסה משופרת של מודל הבינה המלאכותית שלה. הדגם החדש המשופר מספק לא רק...
Laravel, המפורסמת בתחביר האלגנטי והתכונות החזקות שלו, מספקת גם בסיס איתן לארכיטקטורה מודולרית. שם…
סיסקו ו-Splunk עוזרות ללקוחות להאיץ את המסע שלהם אל מרכז התפעול האבטחה (SOC) של העתיד עם...
תוכנת כופר שלטה בחדשות בשנתיים האחרונות. רוב האנשים מודעים היטב לכך שהתקפות...

