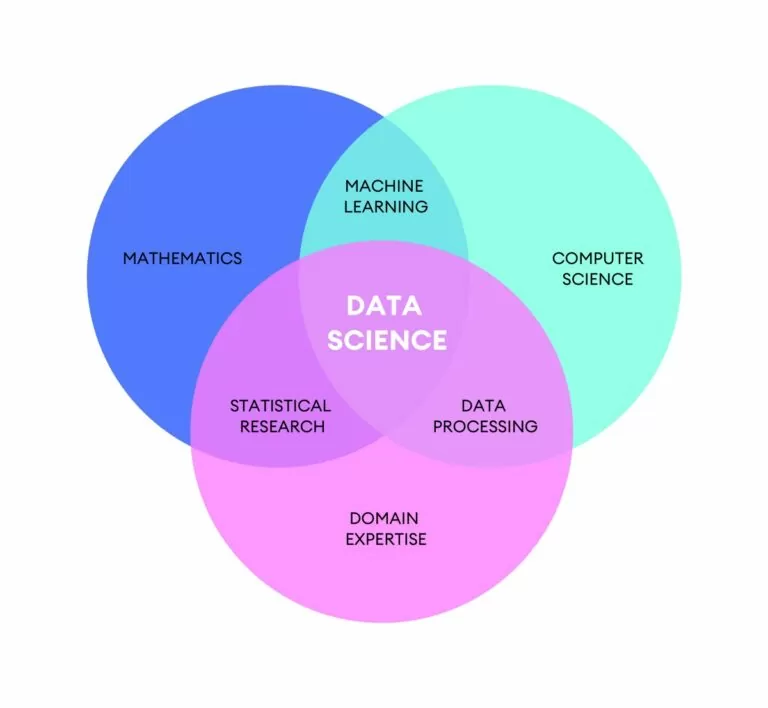
La Data Science، يا ڊيٽا سائنس، هڪ نسبتا نئين سائنس آهي، حقيقت ۾ اهو تقريبا پنجاهه سالن تائين آهي. اهو هڪ انتهائي جاندار ۽ تيزيءَ سان ترقي ڪندڙ تناظر ۾ ترتيب ڏيڻ جي ضرورت مان پيدا ٿئي ٿو. ڊيٽا جي مقدار ۾ واڌ، ڊيٽا کي معني ڏيڻ جي امڪان ۽ صلاحيت، ٺاهيا آهن Data Science.
تاريخي طور تي ڳالهائڻ، ڊيٽا اڪثر ڪري ڪنهن به عمل جي ثانوي پيداوار جي هڪ قسم جي طور تي علاج ڪيو ويو آهي. ڪنهن به صدين کان ڊيٽا گڏ ڪرڻ جو ڪم ڪيو آهي، گهڻو ڪري پنهنجي سهولت لاءِ ڪيو آهي، اڪثر ڪري اهو تصور ڪرڻ کان سواءِ. اڄ هڪ معاشي قدر ڊيٽا جي گڏ ڪرڻ سان منسوب ٿي سگهي ٿو. جيڪڏهن اسان سوچيو، مثال طور، هڪ فارم جو جيڪو سالن کان فصلن، واقعن، پوک، وغيره بابت معلومات گڏ ڪري سگهي ٿو، شايد اهو پنهنجي ڪارپوريٽ تاريخ کي آرڪائيو ڪرڻ لاء ائين ڪيو هجي. جيڪڏهن سڀني فارمن اهو طريقو ڪيو هو، ته اڄ ڀاڻ ڪمپنيون ان مان فائدو حاصل ڪري سگهن ٿيون تحقيق جي مقصدن لاء، يا مارڪيٽنگ جي مقصدن لاء.
جنهن جو واسطو Data Science، هن کي سڏيو ويندو آهي ڊيٽا سائنسدان: في الحال ڪم جي دنيا ۾ سڀ کان وڌيڪ گهربل ماهرن مان هڪ آهي.
ڊيٽا سائنسدان جو ڪم ڊيٽا جو تجزيو ڪرڻ آهي ته جيئن انهن جي اندر ماڊلز کي سڃاڻي سگهجي، اهو آهي، جيڪو آئون رجحان ذريعي موجود ڊيٽا کي بيان ڪريان ٿو. انهن ماڊلز جي سڃاڻپ ڪلائنٽ جي مقصدن لاءِ ڪم ڪندڙ آهي: ڪمپني، عوامي ادارو وغيره ...
تازن سالن ۾، هڪ ڊيٽا مارڪيٽنگ ماڊل تيزي سان پنهنجو پاڻ کي قائم ڪيو آهي جتي ڪو ماڻهو ڊيٽا وڪڻڻ ۾ دلچسپي رکي ٿو ۽ ڪو ٻيو ان کي خريد ڪرڻ ۾.
ڊيٽا جي پيداوار ۾ خاص ڪمپنيون پيدا ڪيون ويون آهن، ۽ ڪمپنيون خريد ڪرڻ ۽ وڪرو ڪرڻ ۾ ماهر آهن مناسب صفائي ۽ ٻيهر پروسيسنگ آپريشن کان پوء. جيڪڏهن اسان پوءِ سوچون ٿا رازداري جي ضابطن بابت، اسان کي محسوس ٿئي ٿو ته موضوع جي پيچيدگي. اڄ اهڙا سخت قانون آهن جيڪي معلومات جي باشعور ۽ احترام سان استعمال لاء سڏين ٿا.
جو هڪ منصوبو Data Science عام طور تي هيٺين قدمن تي مشتمل آهي:
هر هڪ قدم ۾ ڊيٽا سائنسدان خاص ڪمپني جي شعبن سان لهه وچڙ ۾، ۽ ان ڪري اسان اهو چئي سگهون ٿا ته ڊيٽا سائنسدان ڪارپوريٽ حقيقت ۾ مڪمل طور تي ضم ٿي ويو آهي.
ٽيڪنالاجي جي ترقي سان، جي ڊيٽا سائنسدان هو اڪثر پاڻ کي بگ ڊيٽا ۽ مصنوعي ذهانت جي مسئلن کي منهن ڏئي چڪو آهي.
جڏهن اسان بگ ڊيٽا جي باري ۾ ڳالهايون ٿا ته اسان ڊيٽا جو حوالو ڏيون ٿا جنهن ۾ هڪ وڏي قسم آهي، وڌندڙ مقدار ۾ ۽ وڏي رفتار سان. اهو تصور ٽن Vs جي قاعدي طور پڻ سڃاتو وڃي ٿو، جيڪو ٽن اصطلاحن جي چونڊ تي مشتمل آهي جيڪي بگ ڊيٽا جي رجحان کي ان جي ضروري خاصيتن ۾ بيان ڪن ٿا:
حقيقت ۾، وقت سان گڏ ٻيون خاصيتون پڻ شامل ڪيون ويون آهن، جهڙوڪ ڊيٽا جي صداقت ۽ اعتبار جي سڃاڻپ ڪرڻ لاء ڊيٽا جي سچائي.
ڊيٽا جو وڏو مقدار وڏي رفتار تي اچي رهيو آهي، ۽ وڏي قسم جي خاصيت سان، لازمي طور تي ڊيٽا جي تنظيم جي مسئلن کي ڏسجي ٿو.
انھن کي ڀليڪار ۽ پوء انھن کي پروسيسنگ؟ انھن کي ٺاھڻ ۽ پوء انھن کي پروسيسنگ؟
ڊيٽا سسٽم جي تنظيم جا ڪيترائي نمونا پيدا ٿيا، جن پاڻ کي وقت سان قائم ڪيو آهي:
في الحال اهي سڀ کان وڏي پيماني تي استعمال ٿيل نمونا آهن، ۽ ڪيترن ئي ڪيسن ۾ انضمام جو حل غالب آهي، يعني مختلف پروجيڪٽ مختلف جمع ڪرڻ جا طريقا استعمال ڪري سگھن ٿا ۽ پوء بعد ۾ ضم ٿي سگهن ٿا. اهڙيون حالتون ٿي سگهن ٿيون جن ۾ مختلف ڊيٽا گڏ ڪيا ويا آهن مختلف پيراڊمز سان، يا مختلف مجموعا هڪ ئي زندگي جي چڪر جي متضاد مرحلن کي ٺاهي سگهن ٿا.
انهن جي وڏي افاديت جي باوجود، اسان چڱي ريت ڄاڻون ٿا ته پروسيسنگ مشينون يا ڪمپيوٽر بيوقوف آهن. يعني ڪمپيوٽر ڪجھ به نه ٿو ڪري سگهي جيڪڏهن اهو انسان نه آهي ته ڪنهن مسئلي جو تجزيو ڪري، هڪ الگورٿم ٺاهي ۽ ان کي پروگرام ۾ انڪوڊ ڪري.
اهو هميشه ٿي چڪو آهي، جيستائين اسان بابت ڳالهائڻ شروع ڪيو مصنوعي معلومات. درحقيقت، مصنوعي ذهانت مشين ۾ هڪ قسم جي خودمختاري استدلال پيدا ڪرڻ تي مشتمل آهي، جيڪا اها آزاديءَ سان مسئلا حل ڪري سگهي ٿي، يعني انسان جي سڌي هدايت کان سواءِ.
ان اظهار کان اڳ ڪيترائي سال لڳي ويا“مشين ۾ هڪ قسم جي غير معمولي دليل پيدا ڪرڻ“، يعني، مشين جي مڪمل ”زبردستي“ هدايتن جي حالت مان گذري، خود سکيا جي حالت ۾ ڪيترائي سال گذري ويا. ٻين لفظن ۾، مشين خود سکڻ جي قابل ٿي چڪي آهي، سکڻ لاء. ان ڪري اسان وٽ پهچي ويا آهيون مشين سکيا.
مشين لرننگ مصنوعي ذهانت جي هڪ شاخ آهي جنهن ۾ پروگرامر تاريخي ڊيٽا جي مطالعي جي بنياد تي مشين کي تربيتي مرحلي ۾ هلائي ٿو. ھن تربيتي مرحلي جي آخر ۾، ھڪڙو نمونو ٺاھيو ويو آھي جيڪو مسئلن کي حل ڪرڻ ۾ لاڳو ڪري سگھجي ٿو، نئين ڊيٽا سان بيان ڪيو ويو آھي.
مان کلاسي طريقي جو احترام ڪريان ٿو، جتي ڊيٽا سائنسدان لاء ڪم ڪندو هو definish حل الگورتھم، مشين دريافت ڪندو ته ڇا ماڊل ٺاهي ٿو. ڊيٽا سائنسدان کي لازمي طور تي وڌيڪ اثرائتي تربيتي مرحلن کي منظم ڪرڻ جو خيال رکڻو پوندو، وڌيڪ معتبر ۽ وڌيڪ اهم ڊيٽا سان، ۽ انهن کي امتحانن جي تابع ڪرڻ سان تيار ڪيل ماڊل جي صحيحيت جي تصديق ڪرڻ.
مشين لرننگ جي مهرباني، سسٽم جيڪي اسان موبائل ڊوائيسز، انٽرنيٽ، گهر آٽوميشن ۾ استعمال ڪندا آهيون (يا لڳي) وڌيڪ ۽ وڌيڪ ذهين آهن. هڪ سسٽم، جيئن اهو ڪم ڪري ٿو، شايد ان تي ڊيٽا گڏ ڪرڻ جي قابل ٿي سگهي ٿو ۽ استعمال ڪندڙن تي جيڪي ان کي استعمال ڪن ٿا، پوء انهن کي تربيتي مرحلي ۾ استعمال ڪريو ۽ پوء اڳڪٿين کي وڌيڪ بهتر بڻائي.
Ercole Palmeri: جدت جو عادي
Microsoft Excel ڊيٽا جي تجزيو لاءِ ريفرنس ٽول آهي، ڇاڪاڻ ته اهو ڊيٽا سيٽ کي منظم ڪرڻ لاءِ ڪيتريون ئي خاصيتون پيش ڪري ٿو،…
2017 کان ريئل اسٽيٽ ڪروڊ فنڊنگ جي ميدان ۾ يورپ ۾ اڳواڻن جي وچ ۾ والائنس، سم ۽ پليٽ فارم، مڪمل ٿيڻ جو اعلان ڪري ٿو…
Filament هڪ "تيز رفتار" Laravel ڊولپمينٽ فريم ورڪ آهي، ڪيترن ئي مڪمل اسٽيڪ اجزاء مهيا ڪري ٿو. اهو عمل کي آسان ڪرڻ لاء ٺهيل آهي ...
"مون کي پنهنجي ارتقاء کي مڪمل ڪرڻ لاء واپس اچڻ گهرجي: مان پاڻ کي ڪمپيوٽر جي اندر پروجيڪٽ ڪندس ۽ خالص توانائي بڻجي ويندو. هڪ ڀيرو آباد ٿيو ...
گوگل ڊيپ مائنڊ پنهنجي مصنوعي ذهانت واري ماڊل جو هڪ بهتر ورزن متعارف ڪرائي رهيو آهي. نئون سڌريل ماڊل نه رڳو مهيا ڪري ٿو…
Laravel، ان جي خوبصورت نحو ۽ طاقتور خصوصيتن لاء مشهور، پڻ ماڊيولر فن تعمير لاء هڪ مضبوط بنياد فراهم ڪري ٿو. اتي…
سسڪو ۽ اسپلڪ مدد ڪري رهيا آهن گراهڪن کي پنهنجي سفر کي تيز ڪرڻ ۾ مستقبل جي سيڪيورٽي آپريشن سينٽر (SOC) سان…
Ransomware گذريل ٻن سالن کان خبرن تي ڇانيل آهي. گهڻا ماڻهو چڱي ريت واقف آهن ته حملا ...

