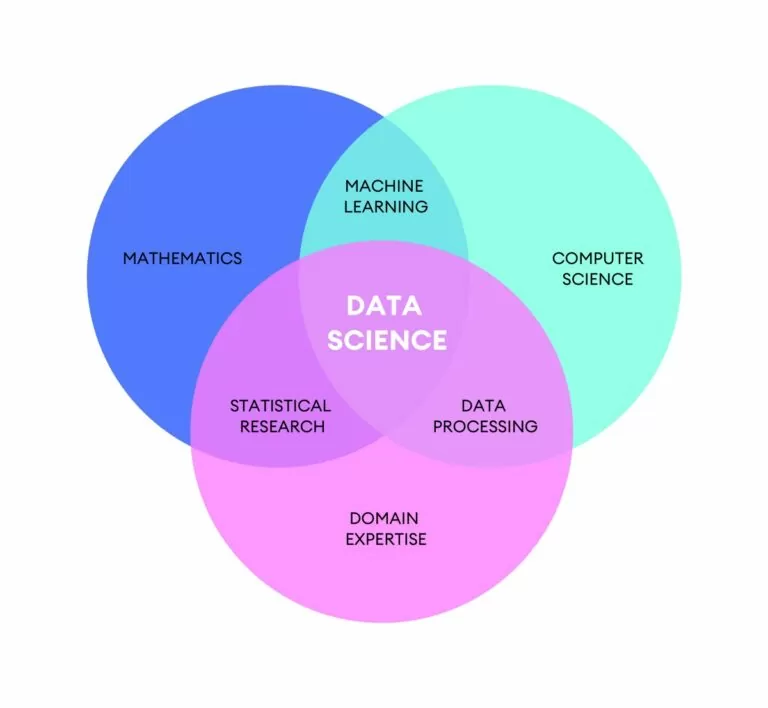
La Data Science, o Data Science, ay isang medyo bagong agham, sa katunayan ito ay nasa loob ng halos limampung taon. Ito ay nagmumula sa pangangailangang maglagay ng kaayusan sa isang napakasigla at mabilis na umuusbong na konteksto. Ang paglaki sa dami ng data, ang posibilidad at kakayahang magbigay ng kahulugan sa datos, ay gumawa ng Data Science.
Sa kasaysayan, ang data ay madalas na itinuturing bilang isang uri ng pangalawang produkto ng anumang proseso. Sinuman sa paglipas ng mga siglo ay nagtangka upang mangolekta ng data, ginawa ito pangunahin para sa kanilang sariling kaginhawahan, kadalasan nang hindi naiisip na ngayon ang isang pang-ekonomiyang halaga ay maaaring maiugnay sa isang koleksyon ng data. Kung iisipin natin, halimbawa, ang isang sakahan na sa paglipas ng mga taon ay maaaring nangolekta ng impormasyon sa mga pananim, kaganapan, paghahasik, atbp., marahil ay nagawa ito upang i-archive ang kasaysayan ng kumpanya nito. Kung ginawa ng lahat ng mga sakahan ang pamamaraang iyon, ang mga kumpanya ng pataba ngayon ay maaaring makinabang mula dito para sa mga layunin ng pananaliksik, o para sa mga layunin ng marketing.
Ang nakikitungo sa Data Science, tinawag siya siyentipiko ng data: kasalukuyang isa sa mga pinaka hinahangad na propesyonal sa mundo ng trabaho.
Ang gawain ng data scientist ay pag-aralan ang data upang matukoy ang mga modelo sa loob ng mga ito, iyon ay, kung ano ang ipinahayag ko ang data na magagamit sa pamamagitan ng trend. Ang pagkakakilanlan ng mga modelong ito ay gumagana sa mga layunin ng kliyente: kumpanya, pampublikong katawan atbp ...
Sa mga nakalipas na taon, ang isang modelo ng pagmemerkado ng data ay lalong naging matatag kung saan ang isang tao ay interesado sa pagbebenta ng data at may ibang tao sa pagbili nito.
Ang mga kumpanyang dalubhasa sa paggawa ng data ay ipinanganak, at ang mga kumpanya ay nagdadalubhasa sa pagbili at pagbebenta pagkatapos ng naaangkop na paglilinis at muling pagpoproseso ng mga operasyon. Kung iisipin namin ang tungkol sa mga regulasyon sa privacy, napagtanto namin ang pagiging kumplikado ng paksa. Ngayon ay may mga mahigpit na batas na humihiling ng mulat at magalang na paggamit ng impormasyon.
Isang proyekto ng Data Science karaniwang binubuo ng mga sumusunod na hakbang:
Sa bawat hakbang ang siyentipiko ng data nakikipag-ugnayan sa mga partikular na departamento ng kumpanya, at samakatuwid ay masasabi nating ang siyentipiko ng data ay perpektong isinama sa corporate reality.
Sa pagsulong ng teknolohiya, ang siyentipiko ng data madalas niyang nahaharap sa mga problema ng Big Data at Artificial Intelligence.
Kapag pinag-uusapan natin ang Big Data, tinutukoy natin ang data na naglalaman ng napakaraming iba't-ibang, dumarating nang dumarami at mas mabilis. Ang konseptong ito ay kilala rin bilang panuntunan ng tatlong Vs, na binubuo sa pagpili ng tatlong termino na nagpapakilala sa Big Data phenomenon sa mahahalagang tampok nito:
Sa katotohanan, ang iba pang mga kakaiba ay naidagdag din sa paglipas ng panahon, tulad ng pagiging totoo ng data upang matukoy ang pagiging maaasahan at pagiging maaasahan ng data.
Malaking dami ng data na dumarating sa napakabilis, at nailalarawan sa pamamagitan ng mahusay na pagkakaiba-iba, ay kinakailangang humantong sa mga problema sa organisasyon ng data.
Pagtanggap sa kanila at pagkatapos ay pinoproseso ang mga ito? Istruktura ang mga ito at pagkatapos ay pinoproseso ang mga ito?
Ang ilang mga paradigm ng organisasyon ng mga sistema ng data ay ipinanganak, na itinatag ang kanilang mga sarili sa paglipas ng panahon:
Sa kasalukuyan, ang mga ito ang pinakamalawak na ginagamit na mga paradigma, at sa maraming pagkakataon ang solusyon ng integrasyon ay nangingibabaw, ibig sabihin, ang iba't ibang proyekto ay maaaring gumamit ng iba't ibang mga pamamaraan ng akumulasyon at pagkatapos ay isama sa ibang pagkakataon. Maaaring may mga sitwasyon kung saan ang iba't ibang data ay nakolekta na may iba't ibang mga paradigm, o ang iba't ibang mga koleksyon ay maaaring bumuo ng magkadikit na mga yugto ng parehong ikot ng buhay.
Sa kabila ng kanilang malaking pakinabang, alam na alam natin na ang mga makina sa pagpoproseso o mga computer ay hangal. Ibig sabihin, walang magagawa ang computer kung hindi tao ang mag-analyze ng problema, magbalangkas ng algorithm at mag-encode nito sa isang program.
Ito ay palaging ang kaso, hanggang sa nagsimula kaming mag-usap Artipisyal na Katalinuhan. Sa katunayan, ang artipisyal na katalinuhan ay binubuo sa pag-uudyok ng isang uri ng kusang pangangatwiran sa makina, na maaaring humantong dito upang malutas ang mga problema nang nakapag-iisa, iyon ay, nang walang direktang patnubay ng tao.
Tumagal ng ilang taon bago ang ekspresyong "magbuod ng isang uri ng kusang pangangatwiran sa makina", Ibig sabihin, inabot ng ilang taon bago tayo pumasa mula sa isang kondisyon ng kabuuang" sapilitang "pagtuturo ng makina, sa isang kondisyon ng self-learning. Sa madaling salita, ang makina ay nagawang matuto sa sarili, upang matuto. Kaya nakarating na kami sa Pag-aaral ng Machine.
Ang Machine Learning ay isang sangay ng Artificial Intelligence kung saan pinapatakbo ng programmer ang makina sa isang yugto ng pagsasanay batay sa pag-aaral ng makasaysayang data. Sa pagtatapos ng yugto ng pagsasanay na ito, isang modelo ang ginawa na maaaring magamit sa paglutas ng mga problema, ipinaliwanag gamit ang bagong data.
Iginagalang ko ang klasikong diskarte, kung saan nagtatrabaho ang data scientist definish solution algorithm, matutuklasan ng makina kung ano ang bumubuo sa modelo. Dapat pangalagaan ng Data Scientist ang pag-oorganisa ng mga lalong epektibong yugto ng pagsasanay, na may mas mayaman at mas makabuluhang data, at ang pag-verify ng bisa ng mga modelong ginawa sa pamamagitan ng pagsasailalim sa mga ito sa mga pagsubok.
Salamat sa Machine Learning, ang mga system na ginagamit namin sa mga mobile device, internet, home automation ay (o tila) mas at mas matalino. Ang isang system, habang gumagana ito, ay maaari ring mangolekta ng data tungkol dito at sa mga gumagamit na gumagamit nito, pagkatapos ay gamitin ang mga ito sa yugto ng pagsasanay at pagkatapos ay higit pang pagbutihin ang mga pagtataya.
Ercole Palmeri: Adik sa inobasyon
Ang Microsoft Excel ay ang reference tool para sa data analysis, dahil nag-aalok ito ng maraming feature para sa pag-aayos ng mga data set,…
Ang Walliance, SIM at platform sa mga pinuno sa Europe sa larangan ng Real Estate Crowdfunding mula noong 2017, ay nag-anunsyo ng pagkumpleto…
Ang filament ay isang "pinabilis" na framework ng pag-develop ng Laravel, na nagbibigay ng ilang full-stack na bahagi. Ito ay dinisenyo upang gawing simple ang proseso ng…
«Kailangan kong bumalik upang kumpletuhin ang aking ebolusyon: Ipapakita ko ang aking sarili sa loob ng computer at magiging purong enerhiya. Kapag nanirahan sa…
Ang Google DeepMind ay nagpapakilala ng pinahusay na bersyon ng modelo ng artificial intelligence nito. Ang bagong pinahusay na modelo ay nagbibigay hindi lamang…
Ang Laravel, na sikat sa eleganteng syntax at malalakas na feature nito, ay nagbibigay din ng matatag na pundasyon para sa modular na arkitektura. doon…
Tinutulungan ng Cisco at Splunk ang mga customer na mapabilis ang kanilang paglalakbay sa Security Operations Center (SOC) ng hinaharap na may…
Nangibabaw ang Ransomware sa balita sa nakalipas na dalawang taon. Alam na alam ng karamihan na ang mga pag-atake ay...

