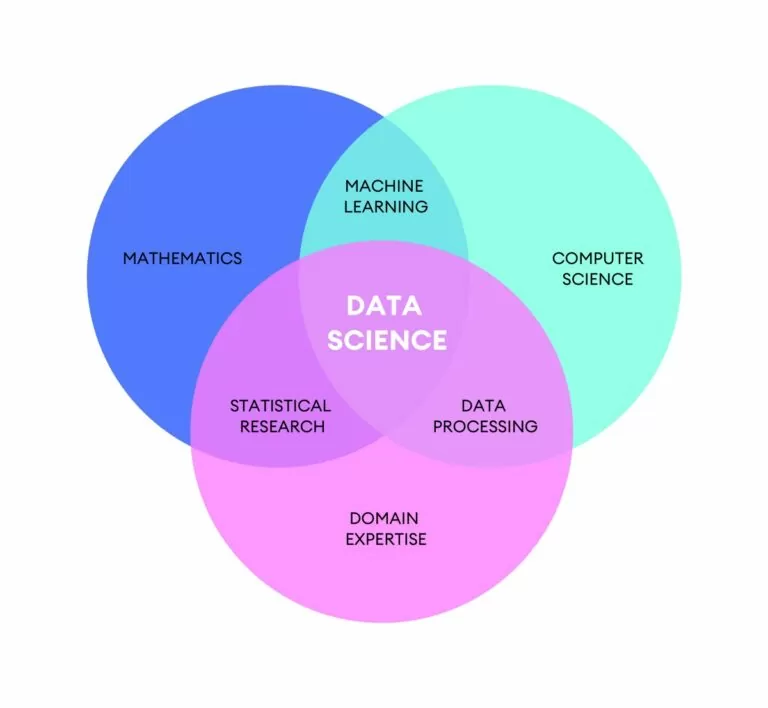
La Data Science، یا ڈیٹا سائنس، ایک نسبتاً نئی سائنس ہے، درحقیقت یہ تقریباً پچاس سال سے ہے۔ یہ ایک انتہائی جاندار اور تیزی سے ارتقا پذیر سیاق و سباق میں ترتیب دینے کی ضرورت سے پیدا ہوتا ہے۔ اعداد و شمار کے حجم میں اضافے، اعداد و شمار کو معنی دینے کے امکانات اور صلاحیت نے اس کو بنایا ہے۔ Data Science.
تاریخی طور پر، ڈیٹا کو اکثر کسی بھی عمل کی ایک قسم کی ثانوی مصنوعات کے طور پر سمجھا جاتا ہے۔ صدیوں کے دوران کسی نے بھی ڈیٹا اکٹھا کرنے کا بیڑا اٹھایا ہے، بنیادی طور پر اپنی سہولت کے لیے ایسا کیا ہے، اکثر اس کا تصور کیے بغیر۔ آج ایک اقتصادی قدر کو اعداد و شمار کے مجموعہ سے منسوب کیا جا سکتا ہے۔. مثال کے طور پر اگر ہم کسی ایسے فارم کے بارے میں سوچتے ہیں جس نے برسوں سے فصلوں، واقعات، بوائی وغیرہ کے بارے میں معلومات اکٹھی کی ہوں، تو شاید وہ اپنی کارپوریٹ تاریخ کو محفوظ کرنے کے لیے ایسا کر سکتا تھا۔ اگر تمام فارموں نے یہ طریقہ اختیار کیا ہوتا تو آج کھاد کی کمپنیاں تحقیقی مقاصد کے لیے یا مارکیٹنگ کے مقاصد کے لیے اس سے فائدہ اٹھا سکتی ہیں۔
جس کے ساتھ معاملہ ہوتا ہے۔ Data Science، اسے بلایا گیا ہے۔ ڈیٹا سائنسدان: فی الحال کام کی دنیا میں سب سے زیادہ مطلوب پیشہ ور افراد میں سے ایک۔
ڈیٹا سائنٹسٹ کا کام ڈیٹا کا تجزیہ کرنا ہے تاکہ ان کے اندر موجود ماڈلز کی شناخت کی جا سکے، یعنی میں ٹرینڈ کے ذریعے دستیاب ڈیٹا کا اظہار کرتا ہوں۔ ان ماڈلز کی شناخت کلائنٹ کے مقاصد کے لیے کام کرتی ہے: کمپنی، پبلک باڈی وغیرہ...
حالیہ برسوں میں، ڈیٹا مارکیٹنگ کے ماڈل نے تیزی سے خود کو قائم کیا ہے جہاں کوئی ڈیٹا بیچنے میں دلچسپی رکھتا ہے اور کوئی اسے خریدنے میں۔
ڈیٹا کی تیاری میں مہارت رکھنے والی کمپنیاں پیدا ہوئیں، اور کمپنیاں مناسب صفائی اور ری پروسیسنگ کے کاموں کے بعد خرید و فروخت میں مہارت رکھتی تھیں۔ اگر ہم رازداری کے ضوابط کے بارے میں سوچتے ہیں، تو ہمیں موضوع کی پیچیدگی کا احساس ہوتا ہے۔ آج ایسے سخت قوانین ہیں جو معلومات کے باشعور اور احترام کے ساتھ استعمال کرنے پر زور دیتے ہیں۔
کا ایک منصوبہ Data Science عام طور پر مندرجہ ذیل اقدامات پر مشتمل ہے:
ہر ایک قدم میں ڈیٹا سائنسدان کمپنی کے مخصوص محکموں کے ساتھ تعامل کرتا ہے، اور اس لیے ہم کہہ سکتے ہیں کہ ڈیٹا سائنسدان کارپوریٹ حقیقت میں بالکل مربوط ہے۔
تکنیکی ترقی کے ساتھ، ڈیٹا سائنسدان اس نے اکثر خود کو بگ ڈیٹا اور مصنوعی ذہانت کے مسائل کا سامنا کرتے ہوئے پایا ہے۔
جب ہم بگ ڈیٹا کے بارے میں بات کرتے ہیں تو ہم اعداد و شمار کا حوالہ دیتے ہیں جس میں ایک بہت بڑی ورائٹی ہوتی ہے، بڑھتی ہوئی حجم میں اور زیادہ رفتار کے ساتھ۔ اس تصور کو تین بمقابلہ کے اصول کے طور پر بھی جانا جاتا ہے، جو تین اصطلاحات کے انتخاب پر مشتمل ہے جو بگ ڈیٹا کے رجحان کو اس کی ضروری خصوصیات میں نمایاں کرتی ہیں:
درحقیقت، وقت کے ساتھ ساتھ دیگر خصوصیات کو بھی شامل کیا گیا ہے، جیسے کہ اعداد و شمار کی صداقت اور اعتبار کی شناخت کے لیے ڈیٹا کی سچائی۔
اعداد و شمار کی بڑی مقدار جو تیز رفتاری سے پہنچتی ہے، اور جس کی خصوصیت بہت زیادہ ہوتی ہے، ضروری طور پر ڈیٹا تنظیم کے مسائل کا باعث بنتی ہے۔
ان کا استقبال کرنا اور پھر ان پر کارروائی کرنا؟ ان کی ساخت اور پھر ان پر کارروائی؟
اعداد و شمار کے نظام کی تنظیم کے کئی نمونے پیدا ہوئے، جو وقت کے ساتھ خود کو قائم کر چکے ہیں:
فی الحال یہ سب سے زیادہ استعمال ہونے والے پیراڈائمز ہیں، اور بہت سے معاملات میں انضمام کا حل غالب رہتا ہے، یعنی مختلف پروجیکٹس جمع کرنے کے مختلف طریقے استعمال کر سکتے ہیں اور پھر بعد میں انضمام ہو سکتے ہیں۔ ایسے حالات ہو سکتے ہیں جن میں مختلف اعداد و شمار کو مختلف نمونوں کے ساتھ اکٹھا کیا جاتا ہے، یا مختلف مجموعے ایک ہی زندگی کے چکر کے متضاد مراحل تشکیل دے سکتے ہیں۔
ان کی بڑی افادیت کے باوجود، ہم اچھی طرح جانتے ہیں کہ پروسیسنگ مشینیں یا کمپیوٹر احمق ہیں۔ یعنی کمپیوٹر کچھ نہیں کر سکتا اگر وہ کسی مسئلے کا تجزیہ کرنے، الگورتھم بنانے اور اسے پروگرام میں انکوڈ کرنے کے لیے انسان نہیں ہے۔
یہ ہمیشہ سے ہوتا رہا ہے، یہاں تک کہ ہم نے بات شروع کی۔ مصنوعی ذہانت. درحقیقت، مصنوعی ذہانت مشین میں ایک قسم کی بے ساختہ استدلال پیدا کرنے پر مشتمل ہے، جس کی وجہ سے وہ آزادانہ طور پر مسائل کو حل کر سکتی ہے، یعنی براہ راست انسانی رہنمائی کے بغیر۔
اظہار سے پہلے کئی سال لگ گئے"مشین میں ایک قسم کی بے ساختہ استدلال پیدا کریں۔"، یعنی، مشین کی مکمل" جبری" ہدایات کی حالت سے، خود سیکھنے کی شرط پر جانے میں کئی سال لگے۔ دوسرے لفظوں میں، مشین خود سیکھنے، سیکھنے کے قابل رہی ہے۔ اس لیے ہم یہاں پہنچے ہیں۔ مشین لرننگ.
مشین لرننگ مصنوعی ذہانت کی ایک شاخ ہے جس میں پروگرامر تاریخی ڈیٹا کے مطالعہ کی بنیاد پر تربیتی مرحلے میں مشین چلاتا ہے۔ اس تربیتی مرحلے کے اختتام پر، ایک ماڈل تیار کیا جاتا ہے جس کا استعمال مسائل کو حل کرنے میں کیا جا سکتا ہے، جس کی وضاحت نئے ڈیٹا کے ساتھ کی جاتی ہے۔
میں کلاسک نقطہ نظر کا احترام کرتا ہوں، جہاں ڈیٹا سائنسدان کام کرتا تھا۔ definish حل الگورتھم، مشین دریافت کرے گی کہ ماڈل کیا بناتا ہے۔ ڈیٹا سائنٹسٹ کو زیادہ سے زیادہ مؤثر اور زیادہ اہم ڈیٹا کے ساتھ، تیزی سے موثر تربیتی مراحل کو منظم کرنے، اور تیار کردہ ماڈلز کو ٹیسٹ کے تابع کر کے ان کی درستگی کی تصدیق کرنے کا خیال رکھنا چاہیے۔
مشین لرننگ کی بدولت، ہم موبائل آلات، انٹرنیٹ، ہوم آٹومیشن میں جو سسٹم استعمال کرتے ہیں وہ زیادہ سے زیادہ ذہین (یا لگتا ہے) ہیں۔ ایک نظام، جیسا کہ یہ کام کرتا ہے، اس پر اور اسے استعمال کرنے والے صارفین کا ڈیٹا بھی جمع کرنے کے قابل ہو سکتا ہے، پھر انہیں تربیتی مرحلے میں استعمال کرتا ہے اور پھر پیشین گوئیوں کو مزید بہتر بنا سکتا ہے۔
Ercole Palmeri: بدعت کا عادی
مائیکروسافٹ ایکسل ڈیٹا کے تجزیے کے لیے ریفرنس ٹول ہے، کیونکہ یہ ڈیٹا سیٹس کو منظم کرنے کے لیے بہت سی خصوصیات پیش کرتا ہے،…
2017 سے ریئل اسٹیٹ کراؤڈ فنڈنگ کے شعبے میں یورپ کے رہنماؤں کے درمیان والینس، سم اور پلیٹ فارم، تکمیل کا اعلان کرتا ہے…
Filament ایک "تیز رفتار" Laravel ڈویلپمنٹ فریم ورک ہے، جو کئی مکمل اسٹیک اجزاء فراہم کرتا ہے۔ یہ عمل کو آسان بنانے کے لیے ڈیزائن کیا گیا ہے…
"مجھے اپنا ارتقاء مکمل کرنے کے لیے واپس آنا چاہیے: میں اپنے آپ کو کمپیوٹر کے اندر پیش کروں گا اور خالص توانائی بنوں گا۔ ایک بار آباد ہو گئے…
گوگل ڈیپ مائنڈ اپنے مصنوعی ذہانت کے ماڈل کا ایک بہتر ورژن متعارف کروا رہا ہے۔ نیا بہتر ماڈل نہ صرف فراہم کرتا ہے…
Laravel، جو اپنے خوبصورت نحو اور طاقتور خصوصیات کے لیے مشہور ہے، ماڈیولر فن تعمیر کے لیے بھی ایک ٹھوس بنیاد فراہم کرتا ہے۔ وہاں…
Cisco اور Splunk صارفین کو مستقبل کے سیکیورٹی آپریشن سینٹر (SOC) تک اپنے سفر کو تیز کرنے میں مدد کر رہے ہیں…
Ransomware پچھلے دو سالوں سے خبروں پر حاوی ہے۔ زیادہ تر لوگ اچھی طرح جانتے ہیں کہ حملے…

