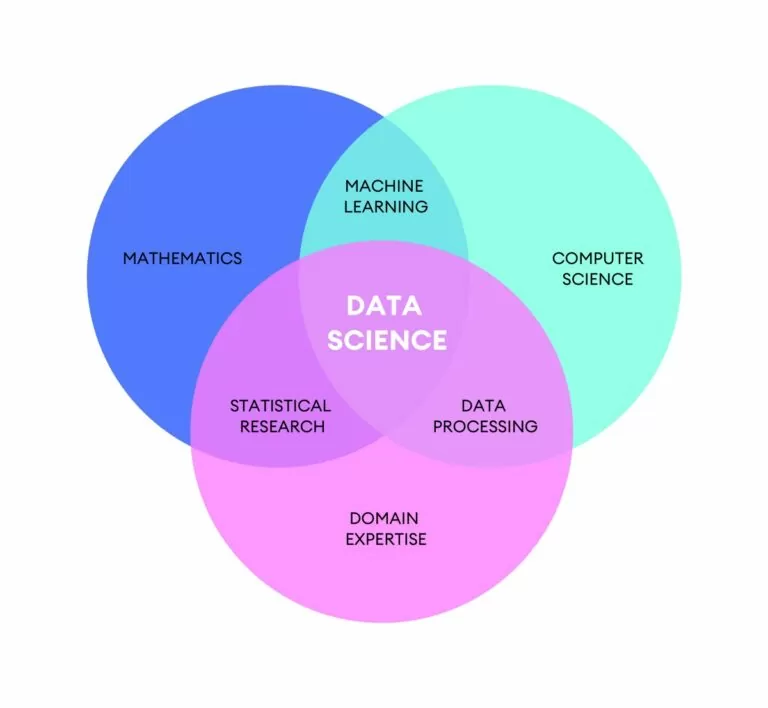
La Data Science, ovvero la Scienza dei Dati, è una scienza relativamente nuova, infatti esiste da una cinquantina d’anni. Nasce dall’esigenza di mettere ordine in un contesto molto vivo, in forte evoluzione. La crescita del volume dei dati, la possibilità e la capacità di dare un significato ai dati, hanno reso sempre più importante e articolata la Data Science.
Storicamente parlando il dato è stato spesso trattato come una sorta di prodotto secondario di qualsiasi processo. Chiunque nei secoli si sia impegnato a raccogliere dati, lo ha fatto principalmente per propria comodità, spesso senza immaginare che oggi a una raccolta di dati potrebbe essere attribuito un valore economico. Se pensiamo ad esempio a un’azienda agricola che negli anni potrebbe aver raccolto informazioni sui raccolti, sugli eventi, sulle semine ecc…, magari potrebbe averlo fatto per archiviare la propria storia aziendale. Se tutte le aziende agricole l’avessero fatto che metodo, allora aziende produttrici di fertilizzanti, oggi ne potrebbero trarre vantaggio per scopi di ricerca, o per scopi di marketing.
Colui che si occupa di Data Science, viene chiamato דאַטן געלערנטער: attualmente una delle figure professionali più ricercate nel mondo del lavoro.
Il compito del data scientist è quello di analizzare dati al fine di individuare modelli al loro interno, cioè cosa esprimo i dati a disposizione mediante l’andamento. L’individuazione di questi modelli è funzionale agli scopi del committente: azienda, ente pubblico ecc…
Negli ultimi anni si è sempre più affermato un modello di commercializzazione dei dati dove qualcuno è interessato a vendere dati e qualcun altro a comprarli.
Sono nate aziende specializzate nella produzione di dati, e aziende specializzate nella compravendita dopo opportune operazioni di pulizia e rielaborazione. Se poi pensiamo alle normative sulla privacy, ci rendiamo conto della complessità dell’argomento. Oggi esistono leggi severe che richiamano ad un uso consapevole e rispettoso delle informazioni.
Un progetto di Data Science solitamente è composto dai seguenti step:
In ogni singolo passo il דאַטן געלערנטער interagisce con dipartimenti specifici aziendali, e quindi possiamo dire che il דאַטן געלערנטער è perfettamente calato nella realtà aziendale.
Con il progresso tecnologico, il דאַטן געלערנטער si è spesso trovato ad affrontare problematiche di Big Data e Intelligenza Artificiale.
Quando si parla di Big Data ci si riferisce a dati che contengono una grande varietà, che arrivano in volumi crescenti e con maggiore velocità. Questo concetto è anche noto come regola delle tre V, che consiste nella scelta di tre termini che caratterizzano il fenomeno Big Data nei tratti essenziali:
In realtà nel tempo si sono aggiunte anche altre particolarità, come la Veridicità dei dati per identificare l’attendibilità e l’affidabilità dei dati.
Grande volume di dati che arrivano a grande velocità, e caratterizzati da grande varietà, portano necessariamente problematiche di organizzazione dei dati.
Accoglierli e poi elaborarli ? Strutturarli e poi elaborarli ?
Sono nati diversi paradigmi di organizzazione dei sistemi di dati, che si sono affermati nel tempo:
Attualmente questi sono i paradigmi maggiormente usati, e in molti casi prevale la soluzione dell’integrazione, cioè diversi progetti potrebbero usare metodologie di accumulo diverse per poi integrarsi in un secondo momento. Si potrebbero avere situazioni in cui si raccolgono dati diversi con paradigmi diversi, oppure diverse raccolte potrebbero costituire fasi attigue di uno stesso ciclo di vita.
Nonostante la loro grande utilità, sappiamo benissimo che le macchine elaboratrici o computer, sono stupidi. Cioè un computer non sa fare niente se non è l’essere umano ad analizzare un problema, formulare un algoritmo e codificarlo in un programma.
Così è sempre stato, finchè non si è iniziato a parlare di אַרטיפיסיאַל ינטעלליגענסע. Infatti l’intelligenza artificiale consiste nell’indurre una specie di ragionamento spontaneo nella macchina, che la possa portare a risolvere problemi in autonomia, cioè senza diretta guida dell’uomo.
Ci sono voluti diversi anni prima di concretizzare l’espressione “indurre una specie di ragionamento spontaneo nella macchina“, cioè ci sono voluti diversi anni prima che si passasse da una condizione di totale istruzione “forzata” della macchina, ad una condizione di auto apprendimento. Cioè si è riusciti a mettere in condizione la macchina di auto apprendere, di imparare. Si è quindi arrivati al Machine Learning.
Il Machine Learning è una branca dell’Intelligenza Artificiale in cui il programmatore guida la macchina in una fase di training basata sullo studio di dati storici. Terminata questa fase di training, viene prodotto un modello che può essere applicato nella risoluzione di problemi, esplicitati con dati nuovi.
Rispetto l’approccio classico, in cui il data scientist lavorava per definire algoritmi risolutivi, sarà la macchina a scoprire cosa compone il modello. Il Data Scientist si deve occupare di organizzare fasi di training sempre più efficaci, con dati più ricchi e significativi, e di verificare la bontà dei modelli prodotti sottoponendoli ai test.
Grazie al Machine Learning, i sistemi che utilizziamo nei dispositivi mobili, internet, domotica sono (o sembrano) sempre più intelligenti. Un sistema, man mano che lavora, potrebbe essere in grado anche di raccogliere dati su di esso e sugli utenti che lo utilizzano, utilizzandoli poi in fase di training per poi ulteriormente migliorare le previsioni.
Ercole Palmeri: כידעש אַדיקטיד
Microsoft Excel איז די רעפֿערענץ געצייַג פֿאַר דאַטן אַנאַליסיס, ווייַל עס אָפפערס פילע פֿעיִקייטן פֿאַר אָרגאַנייזינג דאַטן שטעלט, ...
וואַליאַנס, סים און פּלאַטפאָרמע צווישן די לעאַדערס אין אייראָפּע אין די פעלד פון גרונטייגנס Crowdfunding זינט 2017, אַנאַונסיז די קאַמפּלישאַן ...
פאָדעם איז אַ "אַקסעלערייטיד" לאַראַוועל אַנטוויקלונג פריימווערק, פּראַוויידינג עטלעכע פול-סטאַק קאַמפּאָונאַנץ. עס איז דיזיינד צו פאַרפּאָשעטערן דעם פּראָצעס פון ...
"איך מוזן צוריקקומען צו פאַרענדיקן מיין עוואָלוציע: איך וועל פּרויעקט זיך אין די קאָמפּיוטער און ווערן ריין ענערגיע. אַמאָל געזעצט אין ...
Google DeepMind איז ינטראָודוסינג אַ ימפּרוווד ווערסיע פון זייַן קינסטלעך סייכל מאָדעל. די נייַע ימפּרוווד מאָדעל גיט ניט בלויז ...
Laravel, באַרימט פֿאַר זייַן עלעגאַנט סינטאַקס און שטאַרק פֿעיִקייטן, אויך גיט אַ האַרט יסוד פֿאַר מאַדזשאַלער אַרקאַטעקטשער. דאָרט…
Cisco און Splunk העלפֿן קאַסטאַמערז צו פאַרגיכערן זייער נסיעה צו די זיכערהייט אָפּעראַטיאָנס צענטער (SOC) פון דער צוקונפֿט מיט ...
ראַנסאָמוואַרע האט דאַמאַנייטאַד די נייַעס פֿאַר די לעצטע צוויי יאָר. רובֿ מענטשן זענען געזונט אַווער אַז אנפאלן ...

